【论文阅读】CLIP4Clip:端到端视频检索的CLIP实证研究
论文信息:Luo H , Ji L , Zhong M ,et al.CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval[J]. 2021.DOI:10.48550/arXiv.2104.08860.
源码: https://github.com/ArrowLuo/CLIP4Clip.
文章概述

先说下CLIP:CLIP全称Constrastive Language-Image Pre-training,是OPAI推出的采用对比学习的文本-图像预训练模型。预训练方法即如上图,模型由两个编码器组成,即文本+图像,以大量文本-图像对为输入,走各自编码器得到各自的特征,计算两者之间的cos相似度,让配对的相似度越近,不配对的越远。
回归正题,本文提出了CLIP4Clip模型,将CLIP图文配对的功能以端到端的形式迁移到视频检索中。研究主要包含四个问题:1)对于视频内容检索,图像特征是否足够?2)基于CLIP的大规模视频-文本数据集如何发挥功效?3)模拟视频帧之间的时间依赖性的实际机制是什么?4)模型对视频文本检索任务的超参数敏感性。具体而言,在CLIP的基础上构建了CLIP4Clip,并设计了一个相似度计算器来研究三种相似度计算方法:无参数型、顺序型和紧密型。
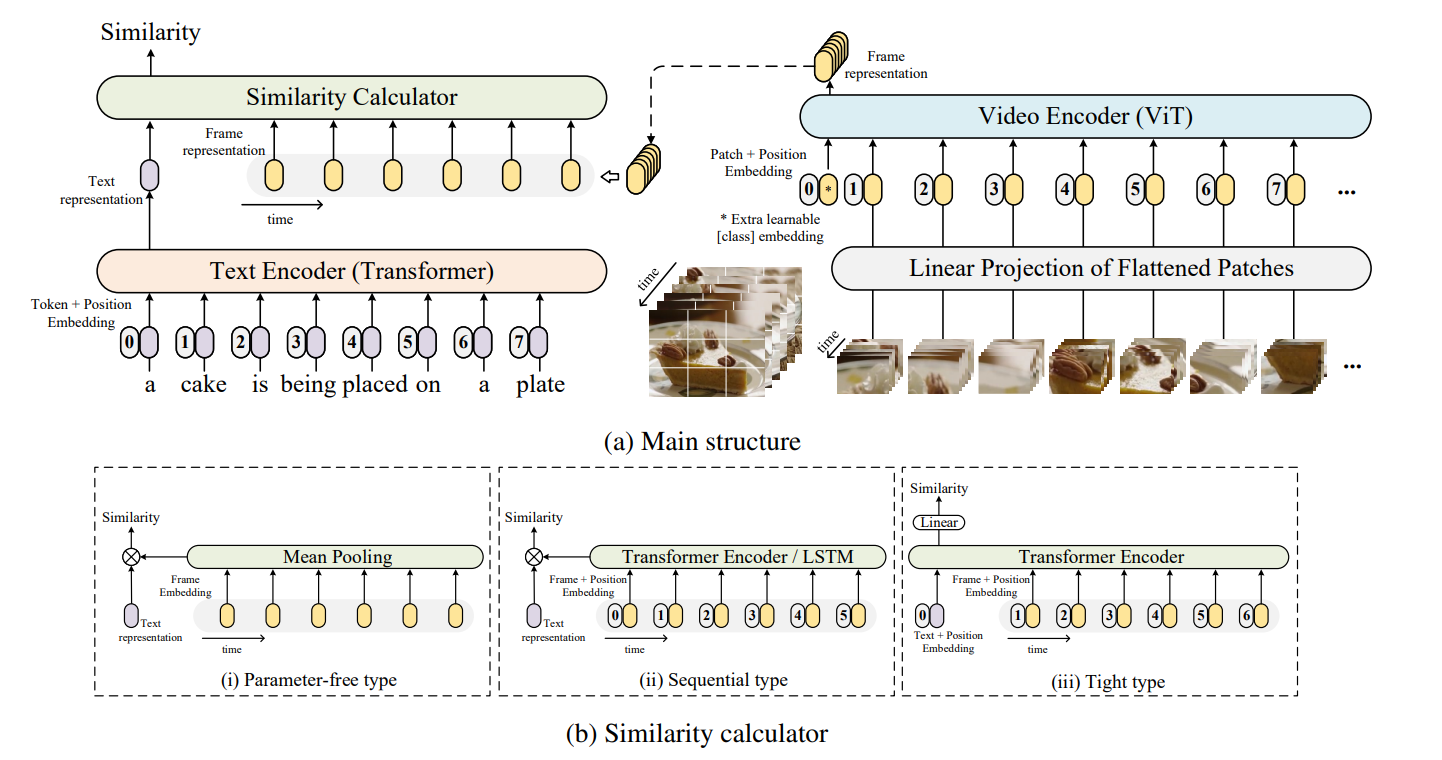
上图展示了CLIP4Clip的架构。此架构由三个部分组成:两个单模型编码器和一个相似度计算器。模型接受视频-文本对作为输入,首先将输入视频拆分为原始的帧(单个图片),然后将这些帧重新集和为水平2D片段序列。这些片段会被映射到1D线性片段序列( 1D sequence of embeddings with a linear patch embedding layer),并输入到图片编码器(如ViT阐述的方案)。最后,相似度计算器预测这些框架的文本表示和表示序列之间的相似度得分。⊗ 意为余弦相似度
实验部分
预测
环境准备:Milvus,存储向量创建索引的数据库;Towhee,用于构建模型推理流水线;
数据集:**MSR-VTT (Microsoft Research Video to Text)** ,公开的视频描述数据集,包含1000条视频极其描述。
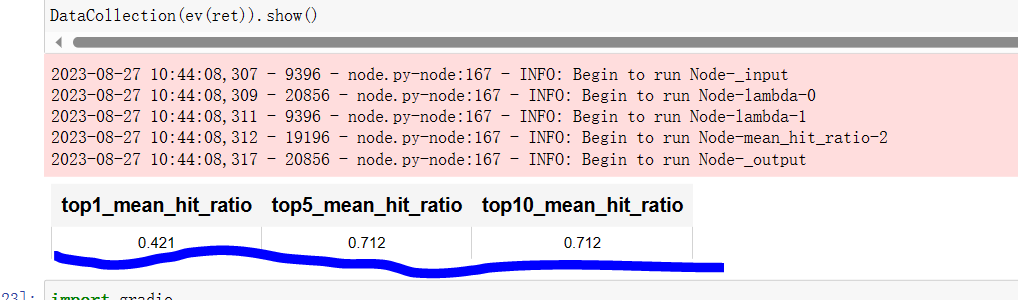
Recall@topk为前k个结果中相关结果的占比,这个数据意味着准确率。假设在前10个结果中这个比率为40%,那么就表示前十个结果中有2个相关结果。返回前1,前5和前10个结果:
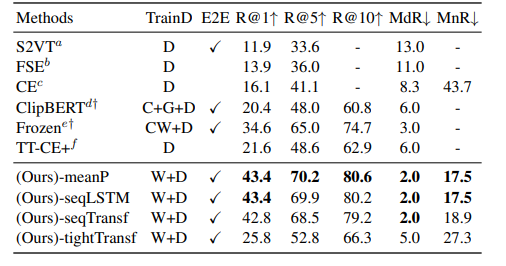
实现
使用gradio搭建一个简单的web应用查看效果。
查询文本:a man talking to a woman
返回视频截图

查询文本:feed a puppy
返回视频截图: