【论文阅读】Grounding Spatio-Temporal Language with Transformers
文章信息:Karch T , Teodorescu L , Hofmann K ,et al.Grounding Spatio-Temporal Language with Transformers[J]. 2021.DOI:10.48550/arXiv.2106.08858.
文章概述
虽然有大量文献研究机器如何学习基础语言,但如何学习时空语言概念的主题在很大程度上仍然是未知的。为了在这一方向上取得进展,我们引入了一种新的时空语言基础任务,目的是学习具身主体行为痕迹的时空描述的意义。这是通过训练一个真值函数来实现的,该函数预测描述是否与给定的观察历史相匹配。这些描述包括过去时和现在时的时间扩展谓词以及对场景中对象的时空引用。为了研究架构偏差在该任务中的作用,我们训练了几个模型,包括多模态Transformer架构;后者在空间和时间上实现了单词和对象之间不同的注意力计算。我们在两类泛化上测试模型:1)对随机伸出句子的泛化;2)归纳到语法原语。我们观察到,在我们的transformer的注意力计算中保持对象身份有助于在总体上实现良好的泛化性能,并且在单个令牌中汇总对象跟踪对性能的影响很小。
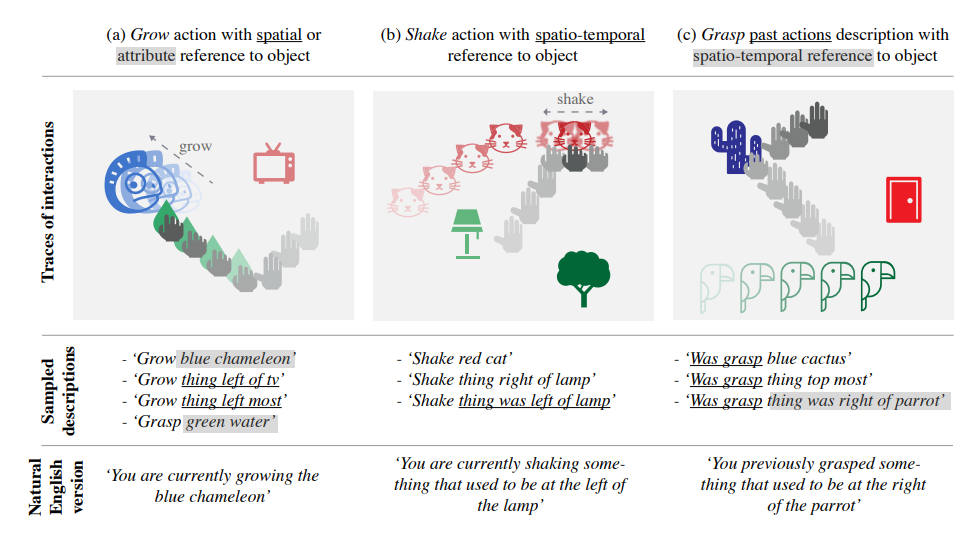
上图为Temporal Playground环境的具象化总结:在每个例子(a、b、c)中,代理(agent)的动作(演示中用手表示)在环境中展开,并在对象和智能体之间产生交互的痕迹。给定这样的跟踪,环境会自动生成一组在跟踪结束时为真的综合语言描述。在(a)中,代理生成一个用空间(下划线)或属性(高亮)引用描述的对象。在(b)中,它摇动用属性、空间或时空(下划线)引用描述的对象。在(c)中,它抓住了一个用属性、空间或时空参考(高亮)描述的对象(过去的动作)。提供自然英文版本是为了便于说明。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 西风の小屋!
相关推荐


评论



