【论文阅读】基于对比学习的视频片段检索
摘要+引言部分
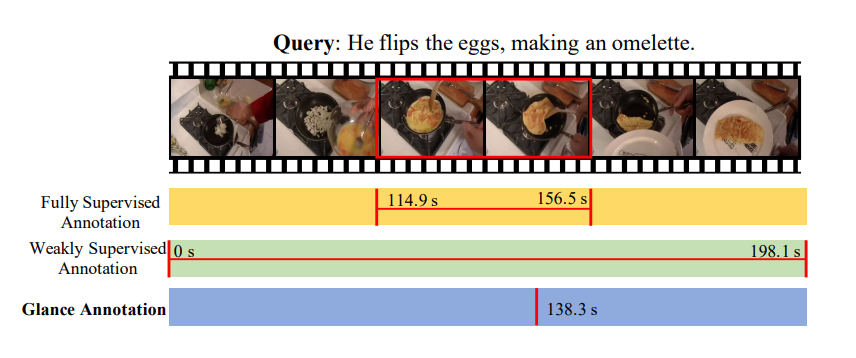
视频语料库片段检索(Video Corpus Moment Retrieval,VCMR)的目的是通过给定查询语句的语义查找对应的视频时域片段。由于视频和文本信息来自两个不同的特征空间,如何实现VCMR有两种基本方式:(i)独立加码每个模型的输出,然后将两个模型输出按顺序执行(原文表述为align,在前几篇论文中则表述为前一模型的输出为后一模型的输入)、(ii)使用细粒度跨模态交互。在本文提出的ReLoCLNet(Retrieval and Localization Network with Contrastive Learning)中采取第一种方法并且引入两个对比学习对象来分别提高视频和文本加码器的工作效率。视频对比学习(Video Contrast Learning)是为了在视频层面最大化视频和查询文本的相关信息(Mutual Information,MI),帧对比学习(Frame Contrast Learning)是为了在视频内部帧层面突出片段域(moment region)。
上文已经说过,要想实现基于查询语句的片段检索有两种方案,一种是分开加码视频和文本,通过特征融合进行匹配(也就是多模型加码,unimodal encoding)。在多模型加码中,查询语句文本被加码为d维度的特征向量,每个向量对应视频的一个片段。另一种是
跨模型交互学习,即将视频视作可视的特征序列,将查询语句视作单词序列来进行互动。后者通常具有更高的准确度,但由于跨模型需要在每条语句与视频集和中每个视频之间运行,且可视特征需要预加码,一般会带来更高的时间代价。下图展现了二者的区别。
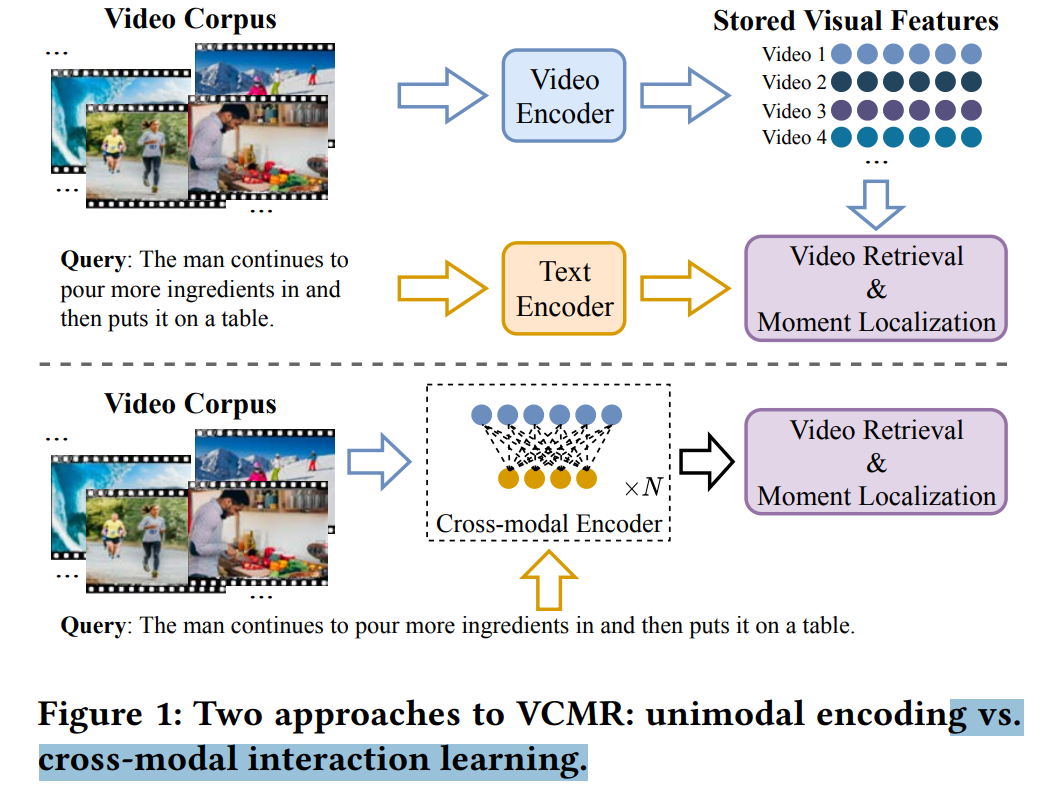
本文将ReLoNet作为基础网络分别加码视频和查询文本,然后再融合二者进行联合定位,然后引入对比学习(CL)模拟语义与视频跨模态交互。对比学习的对象有两个:VideoCL与FrameCL,前者目的是学习视频和文本特征,以便于两边特征能更好地拟合;后者在帧层面模拟细粒度跨模型交互。
主要贡献
使用对比学习替代传统的跨模型交互,首次(2021)指出了实现高效率和高质量VCMR查询之间的矛盾;
通过测量不同粒度的视频和查询之间的相关信息(MI)提出了两个对比学习的对象(VideoCL、FrameCL)在视频和帧层面来模拟跨模型交互
使用数据集TVR进行试验证明ReLoCLNet更加优越。