【论文阅读】mTVL:支持多语言的视频片段检索
论文原标题: Lei J , Berg T L , Bansal M .MTVR: Multilingual Moment Retrieval in Videos[J]. 2021.DOI:10.48550/arXiv.2108.00061.
源码:https://github.com/jayleicn/mTVRetrieval
摘要及引言:
采用数据集MTVR:一种在TVR数据集的基础上增加了相应的中文查询和标题,包含了对21.8K条视频的218K条英语和中文的查询,是最大的视频检索数据集,且支持对话检索(以字幕的形式)。
提出了mXML:一个支持双语言的多片段检索模型,它通过参数共享和限制语言邻域在数据集上执行操作和训练。在XML(by Lei,2020)的基础上加入了参数共享(by Sachan and Neubig,2018;Dong,2015)使得两个语言可以用统一的解码器解码。引入语言邻域限制(by Wang,2018;Kim,2020)到查询输出和字幕嵌入,使得语义相同的不同语言的两句话在嵌入位置上更加相近。
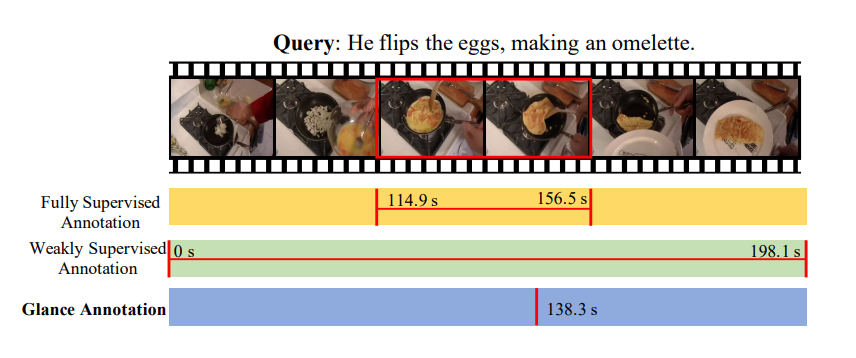
文章首先指出了当前研究的不足之处:仅仅面向单一语言(英语),且不明确一种语言的查询进程和发现是否可以推广到其他语言。举例:Video Corpus Momet Retrieval(VCMR by Escorcia,2020)允许使用者不仅可以追踪到与查询内容最相关的视频,还可以具体定位到视频内的片段。下图(也就是封面图)给出了一个VCMR运行的例子,查询语句中的颜色指示,这些单词是和视频相关(蓝色),视频字幕相关(橙色)还是二者都相关(金色)。

数据集
数据收集
对话字幕
爬取了饭制的中文字幕,确保其与英文原文同样与视频内容有较强的相关性。
查询
花钱雇佣人来做翻译工作,具体来说就是提供视频源文件和谷歌机翻结果,人为将英语原文翻译为中文。。。
数据分析
对比分析中英文平均句长和独有词汇。对于两种语言,对话字幕中含有更多独有词汇,因此要更加多样一些
方法
mXML是在Cross-model Moment Localization(XML)的基础上提出的,相关文章见【】。XML可以提供有效的浅层视频检索和深层的片段定位。为了将单语言的XML模型应用于多语言应用场景,同时提高其效率,我们引入了参数共享和邻域限制(parameter sharing & neighborhood constrains)
解码器和参数共享
查询和上下文解码使用的是自解码器(self-encoder),它由一个自注意层、一个线性层和遵从层标准化的冗余连接组成。我们使用自解码器将每个查询分为两个模块化向量(分别对应了视频自身和字幕)。而对于视频查询,我们不采用一个字节码器和一个作为XML的交叉模型(cross encoder)的形式,而是直接采用两个自解码器的方式,使用第一个解码器的输出和第二个解码器执行工作。