【论文阅读】基于跨模型交互网络的视频片段检索
文章信息:Zhang Z , Lin Z , Zhao Z ,et al.Cross-Modal Interaction Networks for Query-Based Moment Retrieval in Videos[J].ACM, 2019.DOI:10.1145/3331184.3331235.
源码: https://github.com/ikuinen/CMIN
引言部分
对标题【跨模型】的解释
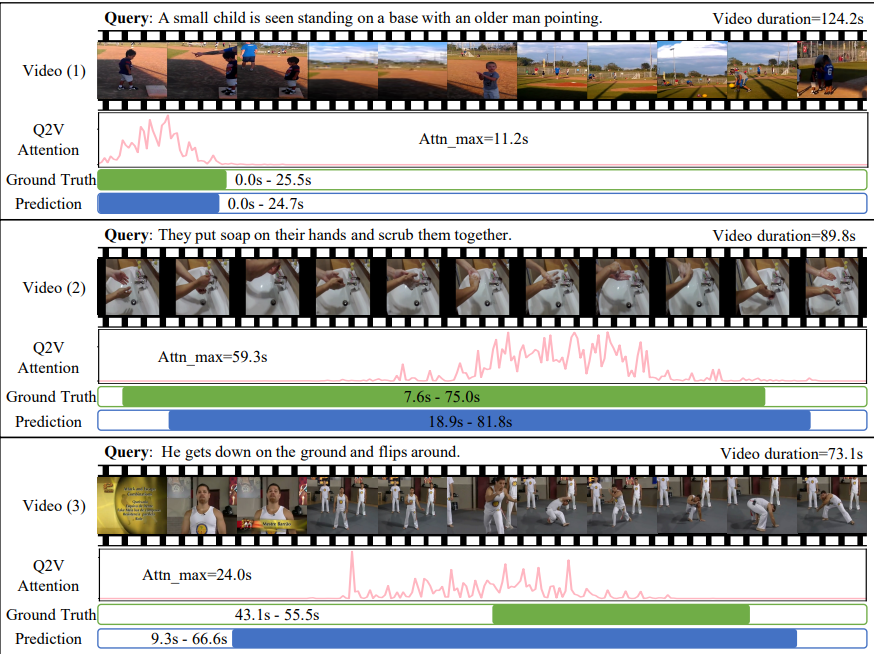
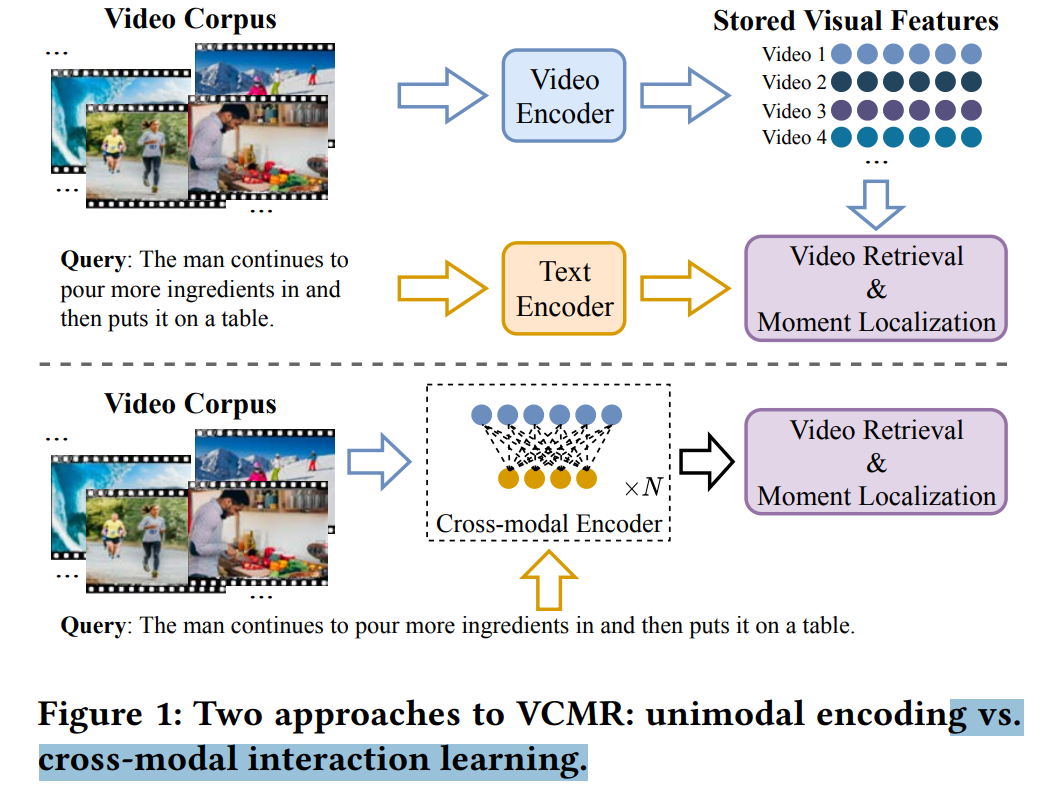
要从一个连续的复杂的视频中定位出一小段特定的片段要比从已定义的集和中找出一个视频要困难的多。在下图所示的例子中,一个句子包含了两个连续的动作,对应了视频中的两段内容。因此正确的视频内容检索需要理解视频以及查询内容,二者缺一不可。这点就需要跨模形(cross-modal)的支持。
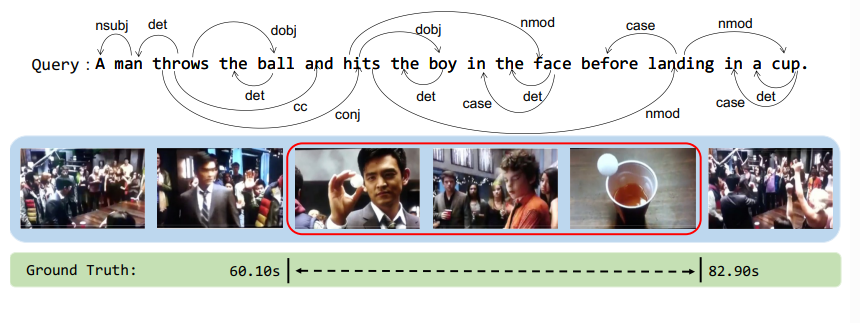
本文对高质量视频检索的考虑
首先
查询内容通常包含了因果时间上的行为,因此学习细粒度查询表示就很重要。目前的方法使用循环神经网络(如GRU)来理解查询语句语义,但它们通常无法顾及句法结构。
本文所采用的是图卷积网络(GCN,Graph convolution network)来处理查询的句法结构,具体说就说如上面图里那样的句法依赖关系,然后沿着每一条依赖连线传递信息来学习查询语句的句法表示。
第二
查询目标片段通常包含有很多其它时间段内的客体交互,就是说某一帧不仅和它相邻的帧关联,也可能和其它距离较远的帧关联。现存的方法应用了基于循环神经网络(RNN)或者用于时间活动检测的区域3D网络(R-C3D)来学习原始视频流中的时空表示,但这还是没办法建立不相邻的帧之间的直接联系。
本文采用了多头自我注意机制(multi-head self-attention mechanism)来捕获视频上下文中不相邻帧间的语义依赖。自注意可以在任意位置发展帧与帧之间的交互,多头设置保证了对复杂依赖关系的充分理解。
第三
高质量的视频检索需要对视频和查询内容的全面理解。以前的方法任然是单方面的(one-stage),所以本文采用多方面的跨模型交互方法来更好的利用视频和查询语句间的潜在联系。
本文首先采用常规的方法对每一帧的句法句法表示进行聚合,然后采用交叉门([cross gate])强化关键内容,弱化不相关内容,再然后发展低秩双线性融合(low-rank bilinear fusion)来学习跨模态语义表示。
主要贡献
- 完成以下挑战设计一个完成VMR的模型:自然语言查询的句法结构、大范围内的视频内容联系、足够的跨模型交互
- 提出语义GCN来应对句法结构(细粒度表示学习)
- 多方面的跨模型