【论文阅读】基于单帧标注的视频片段检索
文章信息:Cui R , Qian T , Peng P ,et al.Video Moment Retrieval from Text Queries via Single Frame Annotation[J].2022.DOI:10.48550/arXiv.2204.09409.
VMR
视频片段检索( video moment retrieval,VMR),旨在根据一段自然语言的描述在未修饰的视频中寻找对应的片段,也称视频定位(localization)或视频挖掘(video grounding)[渣翻]。不同于传统的视频动作定位(Video action localization,VAL),VMR的定位目标延展为自然语言而非预定义的行为类别,其应用场景可以有视频浏览网站和语义视频搜索引擎。
“一眼标”(glance annotation)
fully supervised VMR
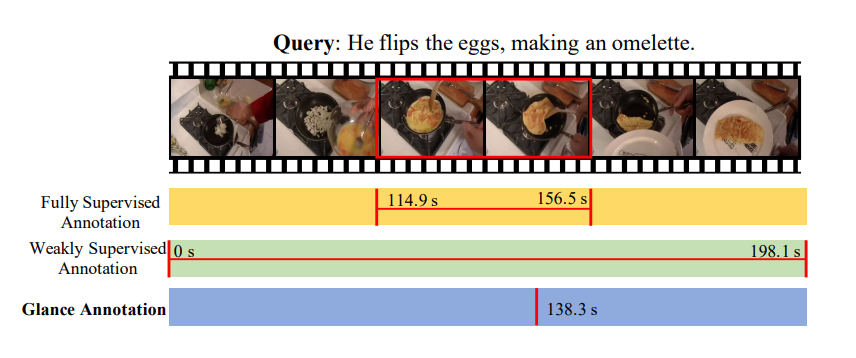
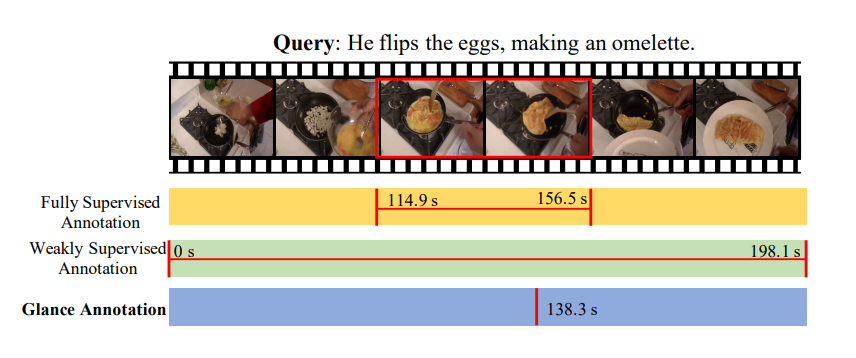
在构造强监督的VMR数据集时,可以用四元组来表述(V,Q,st,ed):
V:视频
Q:查询语句
st:片段开始时间
ed:片段结束时间
这种描述要求数据集构造者先提供视频片段(需要确切的开始和结束时间)以及对应的描述,这点非常依赖人的主观判断,即每个人对某个片段的定义标准不同。另外,这种方式有一个很明显的缺点:巨额时间代价。
weakly supervised VMR
为规避以上问题,弱监督VMR数据集只需要提供视频本身和描述。这牺牲了部分性能,但当标注资源紧缺时可用。
glance annotation
原文作者是认同弱监督模型在表现上的牺牲的,并在强弱监督模型之间提出了glance annotation。事实上,对于一个弱监督的例子,人们还是得看了视频后才能写出查询用的描述,并且多数时候只是看了其中一个小片段就可以知道视频这部分是什么;佐以正确设计的UI,用户就可以以点击一下鼠标的代价通过“一瞥”视频来得出瞬时的时间戳g。
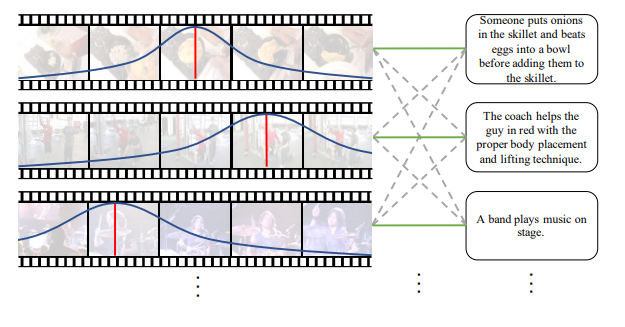
图片:不同的VMR模型训练方法,强监督为每个查询语句定位开始和结尾的位置,弱监督只标记视频-文本对(video-text pair),Glance Annotation标记瞬时时间戳。
ViGA
本文提出的模型基于对比学习(contrastive learning),方法名为Video moment retrieval via Glance Annotation(ViGA)。由于不知道片段开始和结束的具体定位,ViGA遵循大部分弱监督VMR都遵循的多示例学习(Multiple Instance Learning,MIL),它使用V和Q之间的联系作为监督信号。
训练时,让模型学习到视觉和语言两个模态的深度表征,使得语义相近的(V,Q)距离近,反之则距离远。同时,本方法将视频V分割为多个小片C,研究的其实是细化后的(C,Q)的关系,通过基本假设【对于一段长视频,离glance越近,属于该query的概率就越大】,通过高斯先验为每个片段C分配权重。
以下是一个片段C的MIL训练策略例子,绿色实线表示正面联系,灰色虚线表示负面联系